 Easy2Hard-Bench: Standardized Difficulty Labels for Profiling LLM Performance and Generalization
Easy2Hard-Bench: Standardized Difficulty Labels for Profiling LLM Performance and Generalization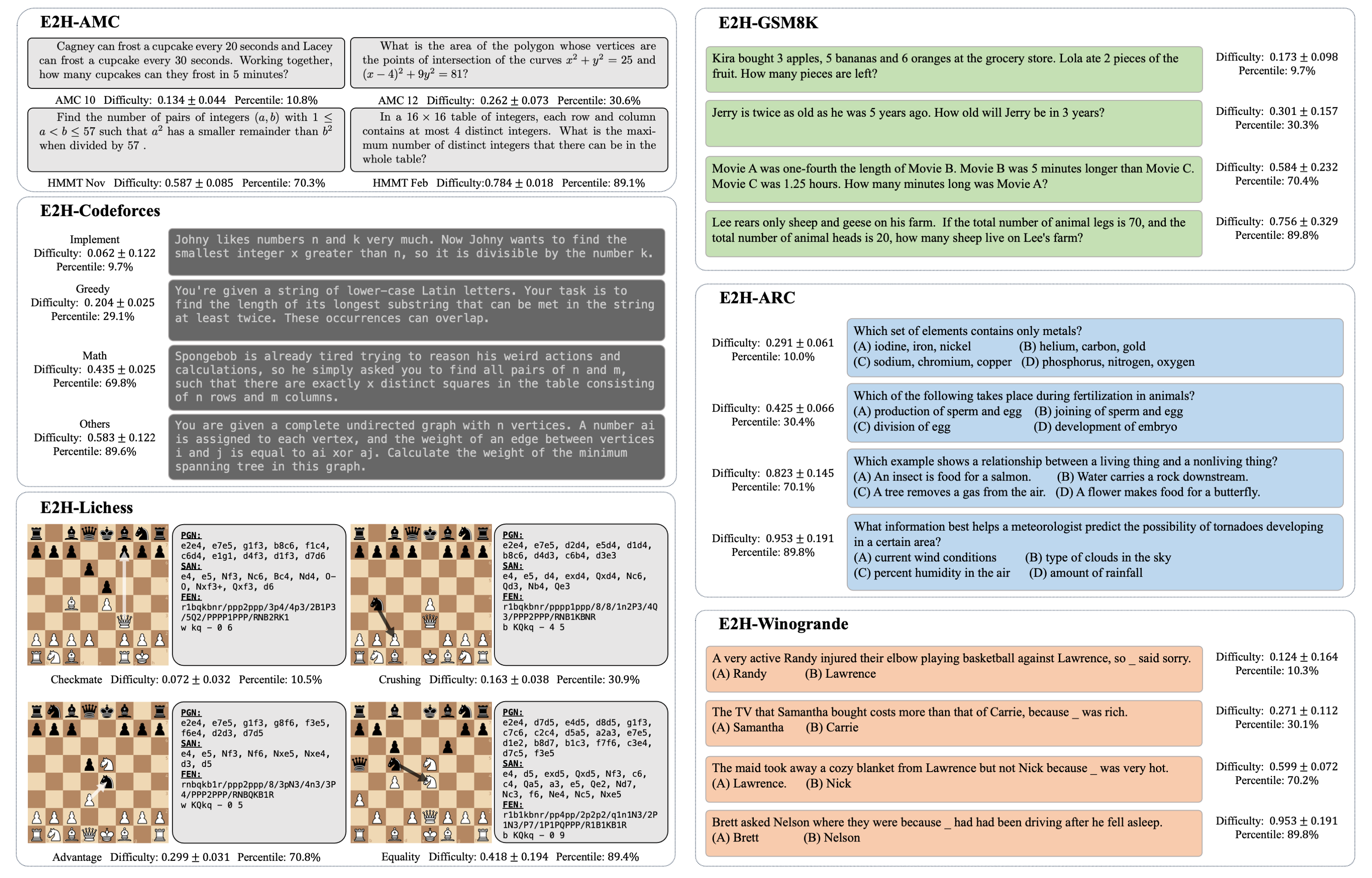
Despite the abundance of datasets available for assessing large language models (LLMs), the scarcity of continuous and reliable difficulty labels for individual data points, in most cases, curtails their capacity to benchmark model generalization performance across different levels of complexity. Addressing this limitation, we present Easy2Hard, an innovative collection of 6 benchmark datasets featuring standardized difficulty labels spanning a wide range of domains, such as mathematics and programming problems, chess puzzles, and reasoning questions, providing a much-needed tool for those in demand of a dataset with varying degrees of difficulty for LLM assessment. We estimate the difficulty of individual problems by leveraging the performance data of many human subjects and LLMs on prominent leaderboards. Harnessing the rich human performance data, we employ widely recognized difficulty ranking systems, including the Item Response Theory (IRT) and Glicko-2 models, to uniformly assign difficulty scores to problems. The Easy2Hard datasets distinguish themselves from previous collections by incorporating a significantly higher proportion of challenging problems, presenting a novel and demanding test for state-of-the-art LLMs. Through extensive experiments conducted with six state-of-the-art LLMs on the Easy2Hard datasets, we offer valuable insights into their performance and generalization capabilities across varying degrees of difficulty, setting the stage for future research in LLM generalization.
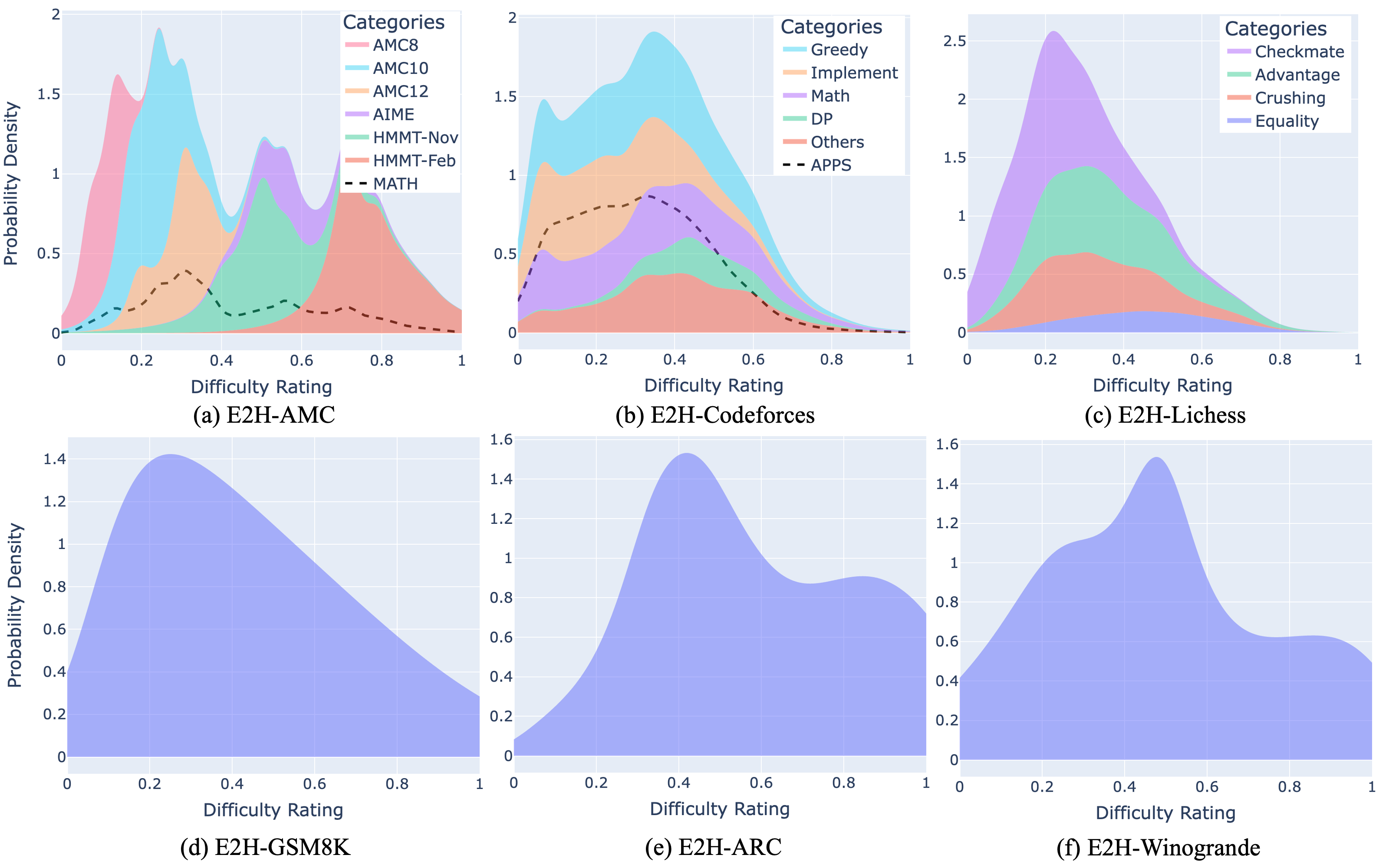
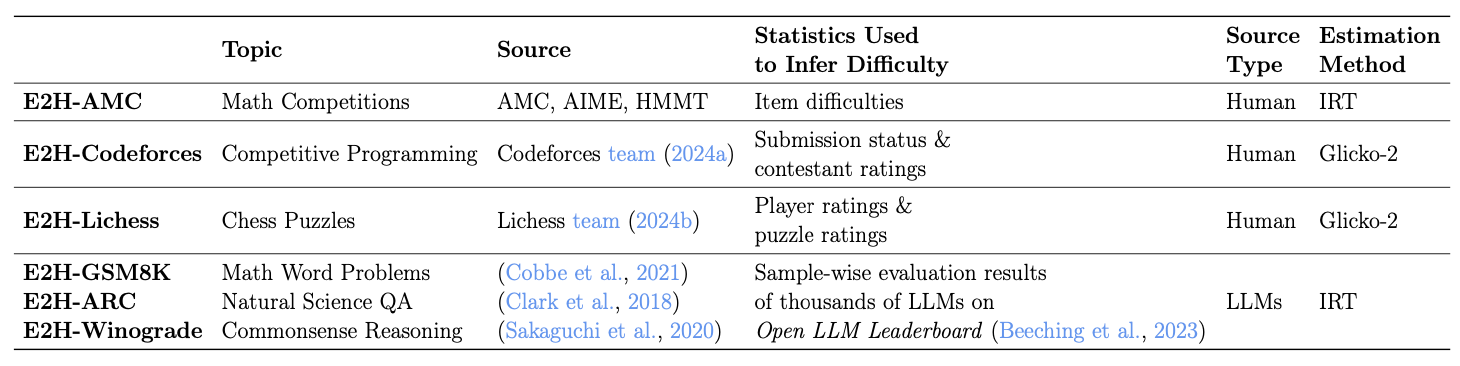
The Easy2Hard-Bench spans six distinct domains, including mathematics, programming, chess, and various reasoning tasks. These diverse tasks encompass a broad spectrum of prevalent cognitive challenges for LLMs. The problems in each dataset of Easy2Hard-Bench are annotated with a numerical value as difficulty estimation.
We find data sources of problems with abundant publicly available human performance statistics, which serve as a robust basis for difficulty estimation. For those datasets on which human performance is inaccessible in large scale, we use the evaluation results by LLMs from Open LLM Leadearboad as surrogate.
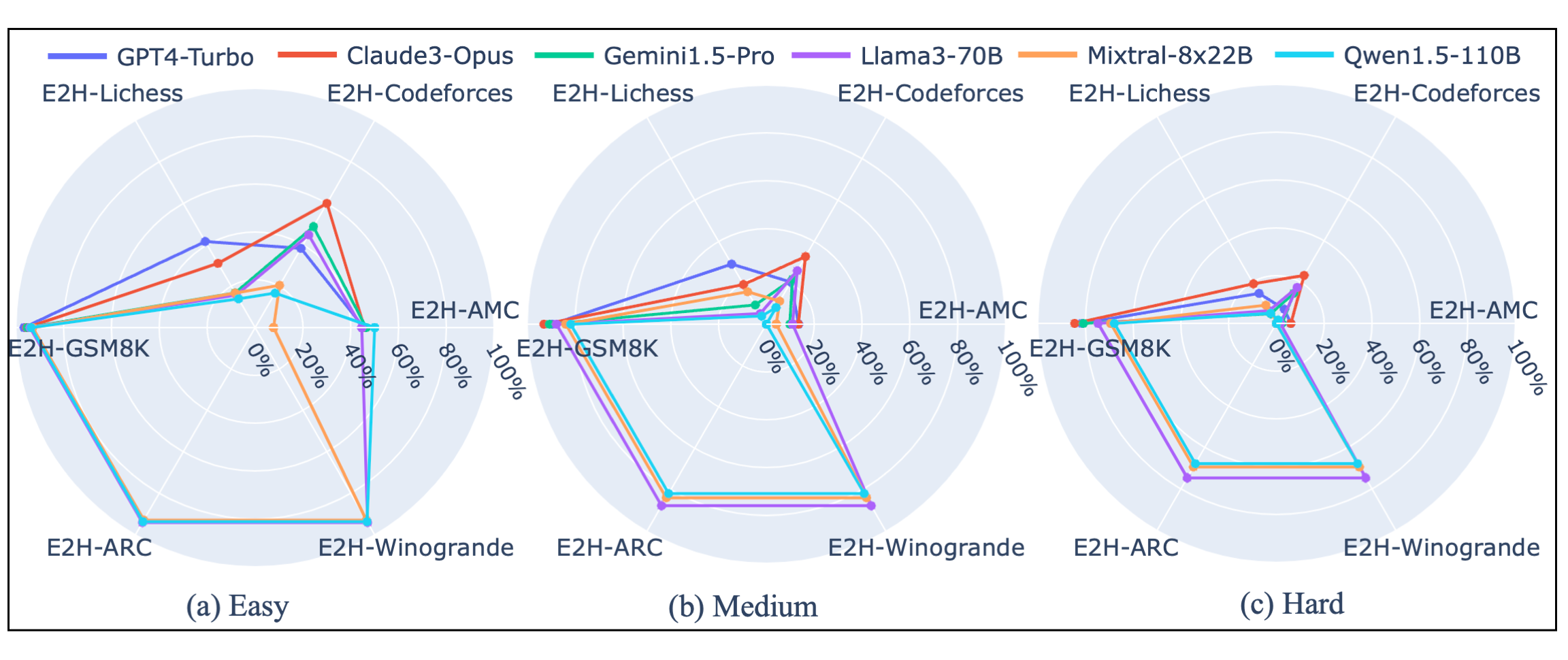
In light of the novel and challenging problems presented in our Easy2Hard-Bench, we select 6 SoTA LLMs for evaluation. We begin by presenting the performance of LLMs on all Easy2Hard-Bench datasets, segmented into easy, medium, and hard difficulty levels. It is evident that performance notably decreases as difficulty increases, validating the effectiveness of our difficulty estimations. The newly curated datasets (E2H-AMC, E2H-Codeforces, E2H-Lichess) are much more challenging than the pre-existing ones, because they extend the difficulty range greatly compared to existing selections.
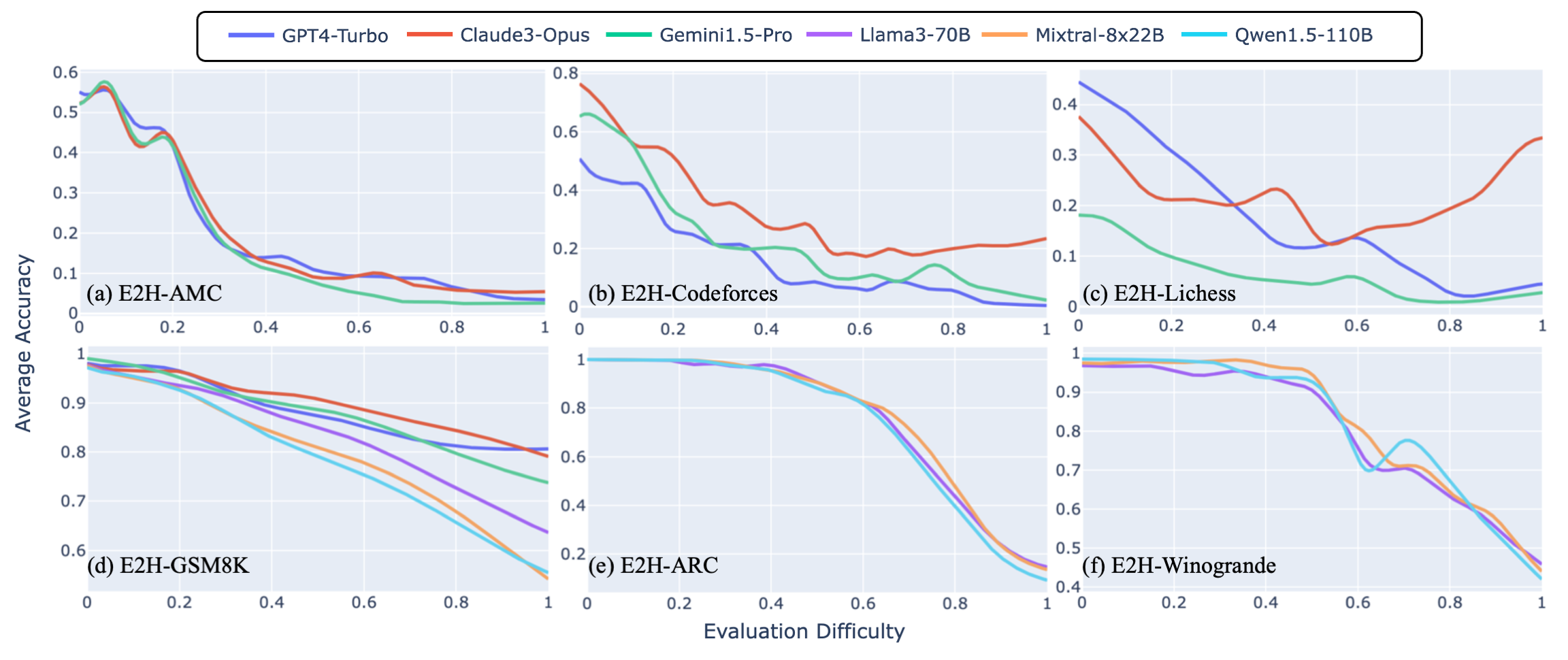
Furthermore, we plot and analyze model behavior against increasing difficulty levels for each dataset. As evaluation difficulty increases, most models show monotonic decreasing accuracies, validating the correctness of provided difficulty ratings. While performance generally declines with difficulty, the extent of this decline varies significantly among models and datasets.
Instead of only assessing the static behavior of specific checkpoints, Easy2Hard-Bench allows for fine-grained profiling of LLMs as they generalize across various training and evaluation difficulties. This also caters to the need to simulate challenging problems like weak-to-strong generalization. To our best knowledge, Easy2Hard-Bench is the first to deliver detailed easy-to-hard generalization results across continuous, wide-range of difficulties on LLMs.
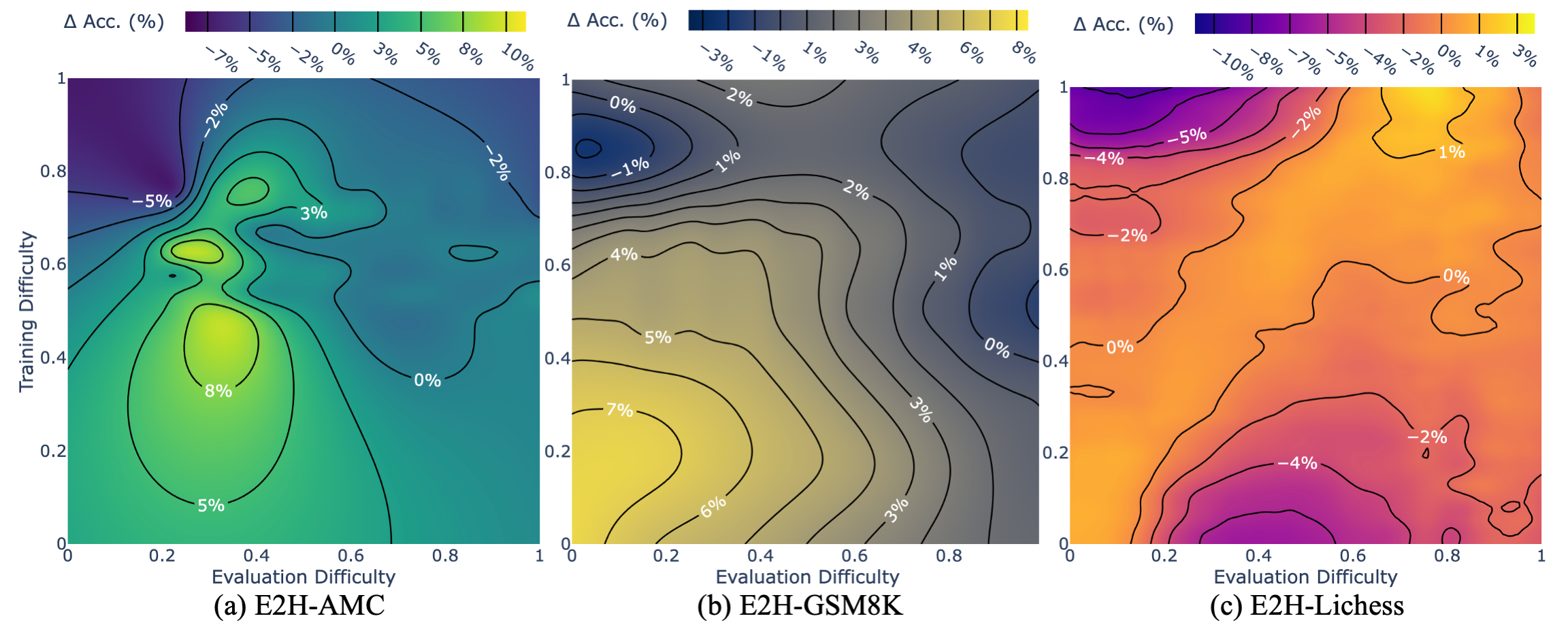
In our preliminary experimental exploration, we focus on Supervised Finetuning (SFT) with relatively smaller LLMs, while deferring more specialized finetuning frameworks for future studies. LLMs are trained on subsets of training splits of varying difficulty (y-axis) via Supervised Fine-Tuning (SFT) and were evaluated across all evaluation difficulties (x-axis). The color gradient represents the performance difference relative to models trained on randomly selected difficulties of same sizes. We observe generalization benefits when training and evaluation difficulties are similar, and training on more challenging samples poses increased generalization difficulties.
@inproceedings{
ding2024easyhardbench,
title={Easy2Hard-Bench: Standardized Difficulty Labels for Profiling {LLM} Performance and Generalization},
author={Mucong Ding and Chenghao Deng and Jocelyn Choo and Zichu Wu and Aakriti Agrawal and Avi Schwarzschild and Tianyi Zhou and Tom Goldstein and John Langford and Anima Anandkumar and Furong Huang},
booktitle={The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track},
year={2024},
url={https://openreview.net/forum?id=iNB4uoFQJb}
}