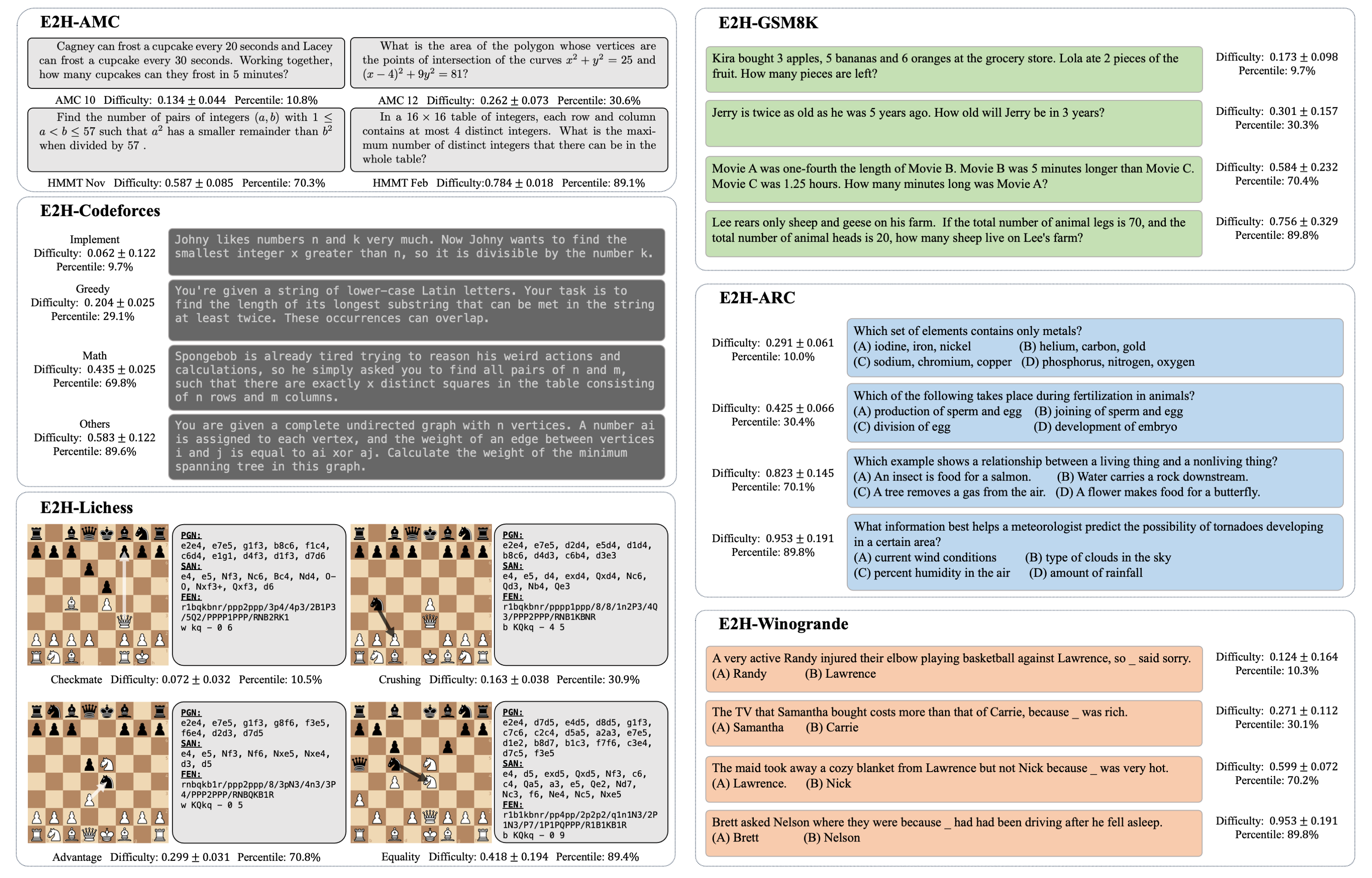
Despite the abundance of datasets available for assessing large language models (LLMs), the scarcity of continuous and reliable difficulty labels for individual data points, in most cases, curtails their capacity to benchmark model generalization performance across different levels of complexity.
Addressing this limitation, we present Easy2Hard, an innovative collection of 6 benchmark datasets featuring standardized difficulty labels spanning a wide range of domains, such as mathematics and programming problems, chess puzzles, and reasoning questions, providing a much-needed tool for those in demand of a dataset with varying degrees of difficulty for LLM assessment.
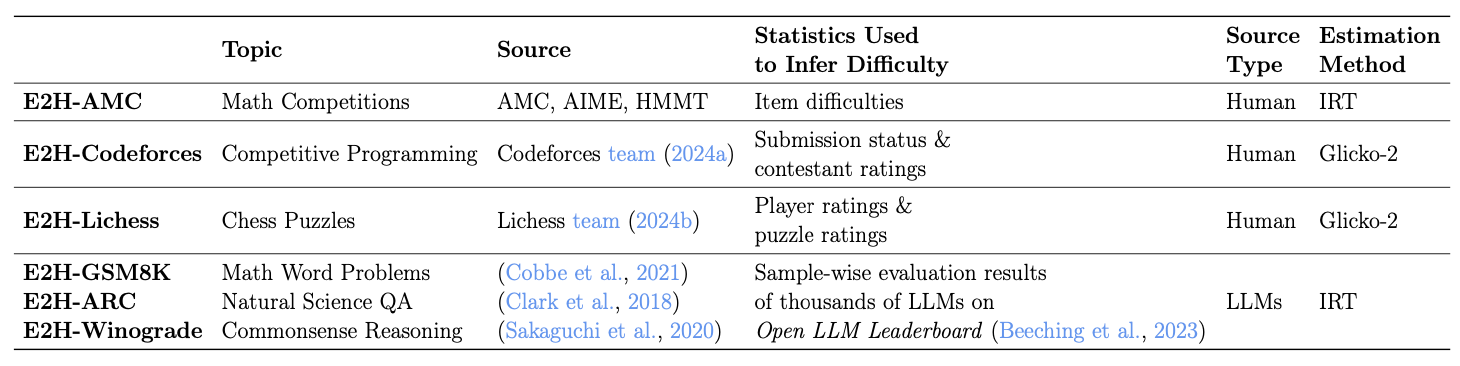
We estimate the difficulty of individual problems by leveraging the performance data of many human subjects and LLMs on prominent leaderboards.
Harnessing the rich human performance data, we employ widely recognized difficulty ranking systems, including the Item Response Theory (IRT) and Glicko-2 models, to uniformly assign difficulty scores to problems.
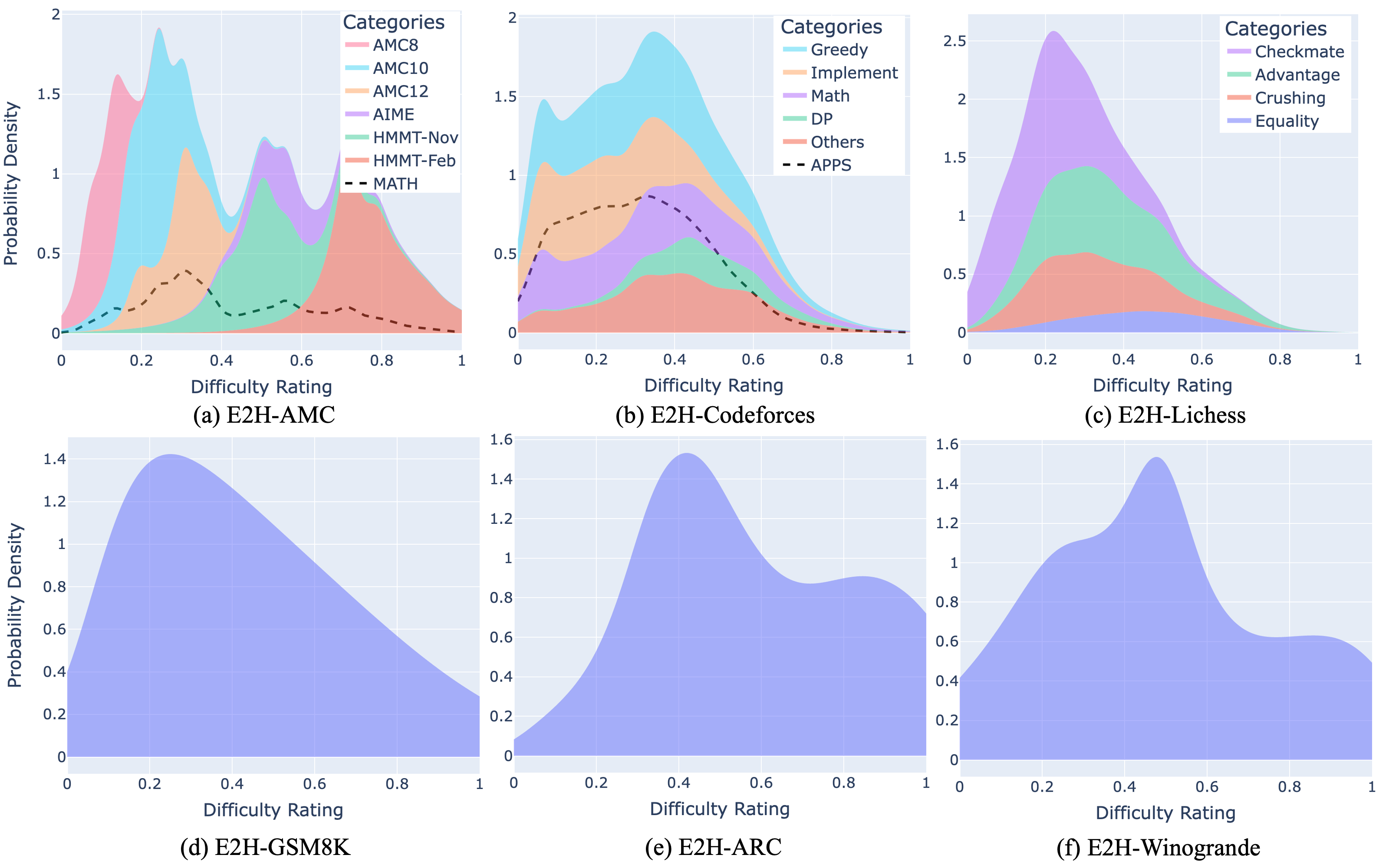
The Easy2Hard datasets distinguish themselves from previous collections by incorporating a significantly higher proportion of challenging problems, presenting a novel and demanding test for state-of-the-art LLMs.
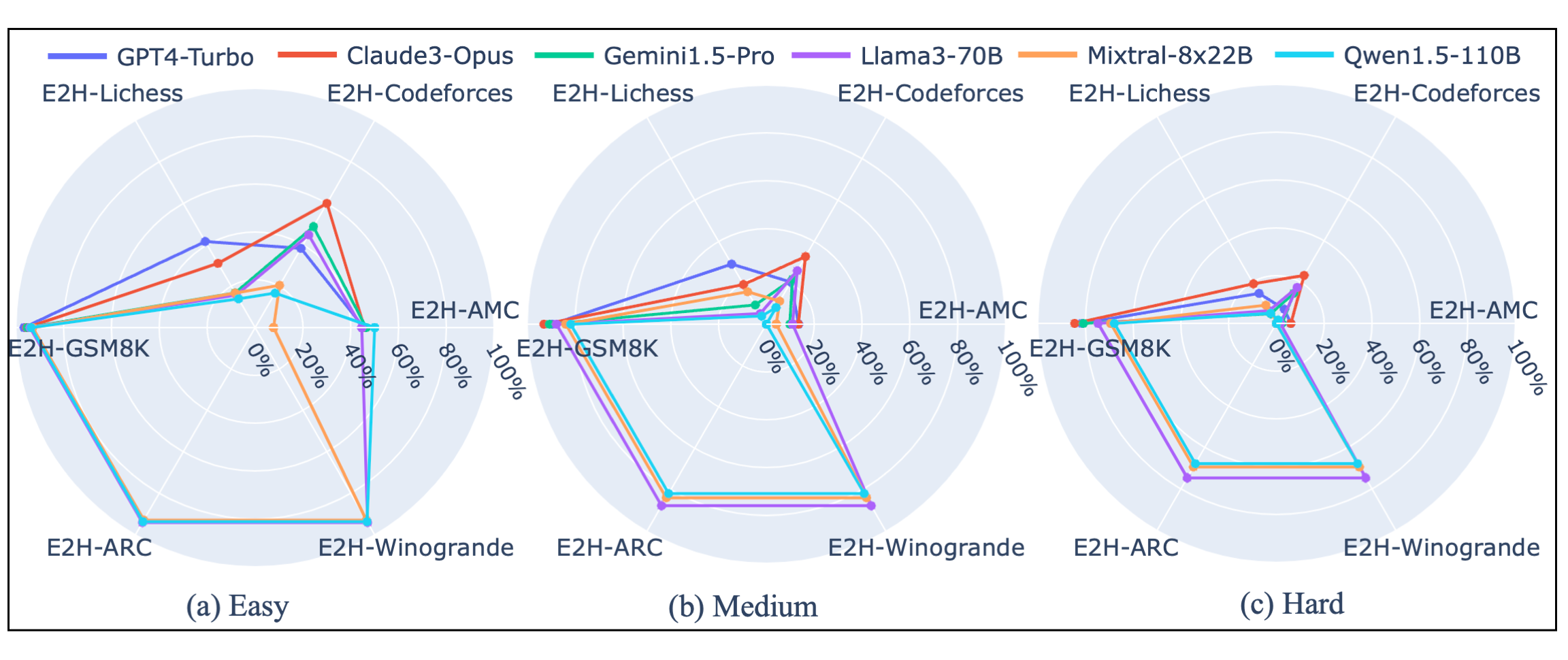
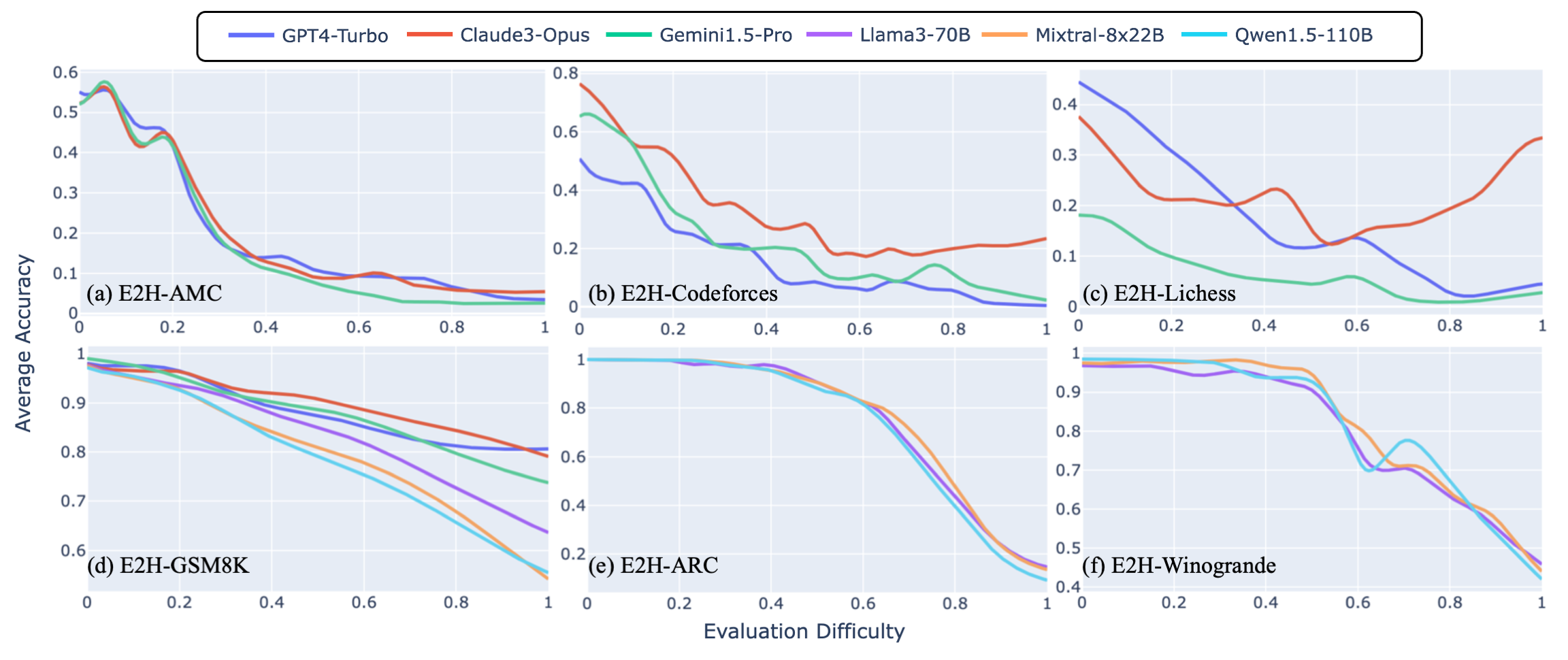
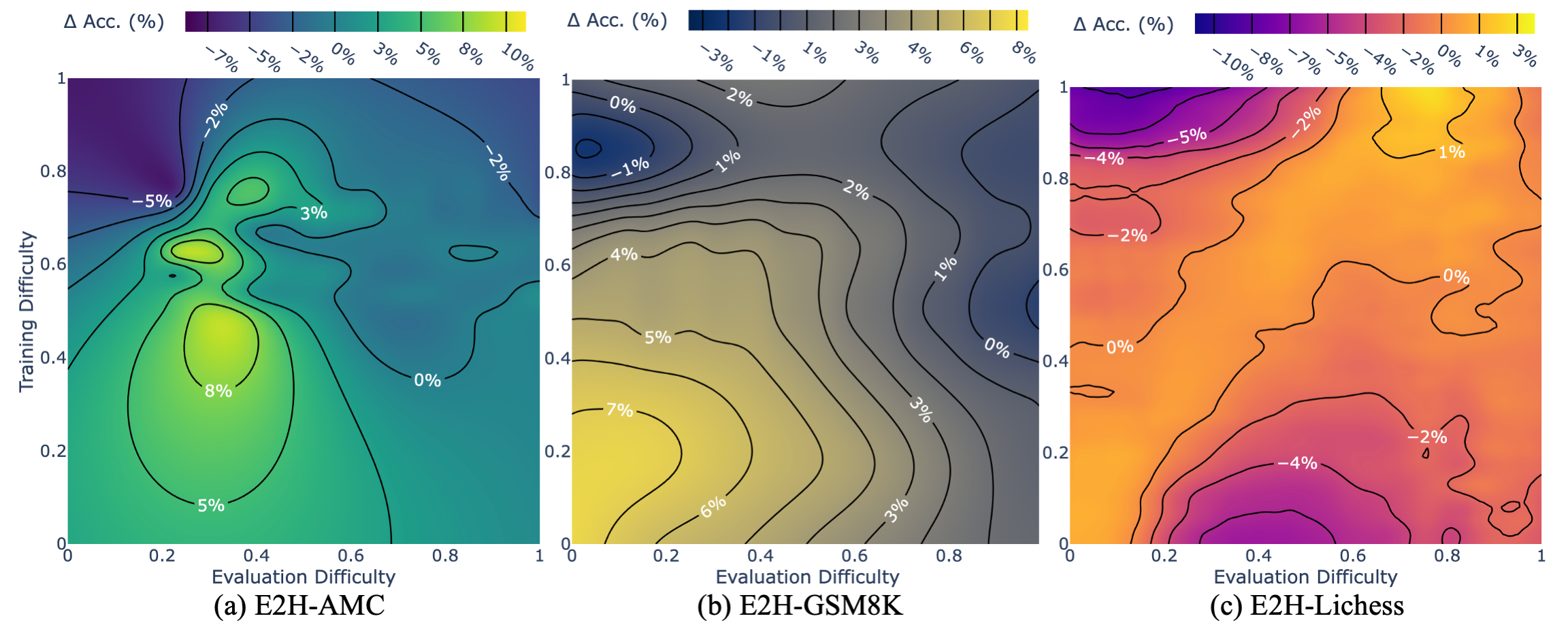
Through extensive experiments conducted with six state-of-the-art LLMs on the Easy2Hard datasets, we offer valuable insights into their performance and generalization capabilities across varying degrees of difficulty, setting the stage for future research in LLM generalization.
 Easy2Hard-Bench: Standardized Difficulty Labels for Profiling LLM Performance and Generalization
Easy2Hard-Bench: Standardized Difficulty Labels for Profiling LLM Performance and Generalization